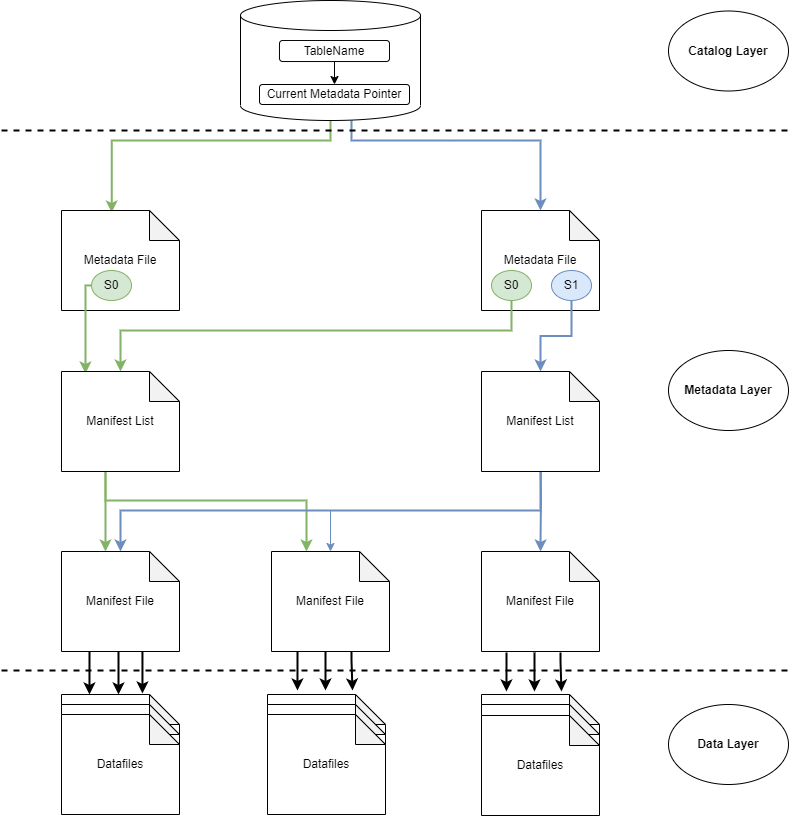
Catalog Layer #
Metadata Layer #
It’s a layer that contains all metadata files for a table in Iceberg. It’s a tree that tracks the datafiles and
metadata about them as well as the operations that resulted in the creation. It’s made up of three file types:
– Manifest files
– Manifest lists
– Metadata files
This layer is essential for efficiently managing large datasets and enable core features such as time travel and schema evolution.
Manifest file #
keep track of file in the data layer (datafiles and delete files) as well as some additional details and statistics about each file such as minimum and maximum values of datafile’s columns.
– Separate subset of manifest files are used to track datafiles and delete file but the schema is identical same
for both.
– During writes, the engine generates statistics and stores them in manifest files that track small batches of data
files. Because these stats are recorded incrementally at write time, producing them is far lighter than in the Hive
table format, where statistics are gathered by long, expensive read jobs that must scan entire partitions—or even
whole tables—before writing partition- or table-level stats.
Information from the manifest files, such as upper and lower bounds for a specific column, null value counts, and partition-specific data, is used by the engine for file pruning.
Manifest list #
It is a snapshot of Iceberg table at a given point in time. It contains a list of **manifest file**,
including the location, the partitions it belongs to, and the upper and lower bounds for partition columns for the
datafiles it tracks.
Query engines interact with the manifest lists to get information about partition specifications that help them skip
the non required manifest files for faster performance.
Metadata file #
It tracks manifest list files. It includes table’s schema, partition information, snapshots, and which snapshot
is current one. Each time a change is made to an Iceberg table, a metadata file is created and is registered as last
version of the metadata file, it helps during scenarios such as:
Concurrent writes (i.e., multiple engines writing data simultaneously).
Also, during read operations, engines will always see the latest version of the table.
Data Layer #
The data layer of an Apache Iceberg table stores the actual table data, consisting mainly of **data files** and
**delete files**. It is responsible for supplying query results, except in certain cases where metadata can answer
queries (e.g., max value lookups). In Iceberg’s tree structure, the data layer forms the leaves.
It is backed by a distributed system such as Hadoop, Amazon Simple Storage (S3), Google Cloud Storage (GCS) and
Azure Data Lake Storage (ADLS), etc.
– **Datafile**
It’s stores data itself at time of this writing three formats are supported by Apache Iceberg, Apache Paraquet,
Apache Avro and Apache ORC.
– **Deleted files**
Tracks records in the dataset that have been deleted.
!!! info
It’s a best practice to keep data in data lake immutable, so you can’t update rows in file in place. Instead,
you need to write a new file.
Two ways are available in Apache Iceberg
– **Copy-On-Write (COW):** the new file is a copy of the old file with the changes reflected in a new copy of it
– **Merge-On-Read (MOR):** a new file that only has the changes written, which engines reading the data then coalesce
MOR delete methods
Positional delete file
Eqaulity delete file



