

When working with Apache Spark, it’s crucial to understand the concepts of logical and physical plans, as they play a pivotal role in the execution of your data processing tasks.
In this blog post, we will break down these two fundamental aspects of Spark’s query optimization process. You can refer to this blog post Spark on k8s to run Spark in Kubernetes.
Spark Internal Execution Flow Overview
Spark internal execution plan comprised of five-step:
- Analysis
- Logical Optimization
- Physical Planning
- Cost Model Analysis
- Code Generation
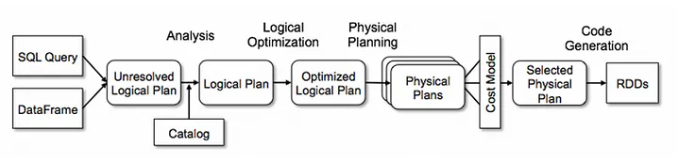
These operations yield to set of plans, including:
- Logical plans
- Physical plans
The objective of these plans is to determine the most optimized strategy to execute your query.
Set up Code Example
To illustrate Spark execution plans, we’ll use the join and orderBy transformations on two DataFrames, as defined in the following code. You can find the complete source code for this article in this GitHub repository.
from pyspark.sql import SparkSession
from pyspark.sql import DataFrame
spark = SparkSession.builder\
.master("local[*]")\
.appName("spark-execution-plan-demo")\
.getOrCreate()
persons = spark.createDataFrame([
(0, "person_1", 0, [100]),\
(1, "person_2", 1, [500, 250, 100]),\
(2, "person_3", 1, [250, 100])])\
.toDF("id", "name", "graduate_program", "spark_status")
graduate_programs = spark.createDataFrame([
(0, "Masters", "School of Information", "UC Berkeley"),\
(2, "Masters", "EECS", "UC Berkeley"),\
(1, "Ph.D.", "EECS", "UC Berkeley")])\
.toDF("id", "degree", "department", "school")
join_result = persons.join(graduate_programs, \
persons["graduate_program"] == graduate_programs["id"], "inner") \
.orderBy("name")Logical Plans
The Logical Plan can be further subdivided into three sub-plans. To obtain the logical plan, we will use the explain method with the extended mode.
Note: If you’re using Spark version 2 use
explain(extended=True)to get the plans.
join_result.explain(mode="extended")
Now, let’s go through the logical sub-plans.
Parsed Logical Plan (Unresolved Logical Plan)
This represents the initial phase in the creation of the Logical Plan, primarily focusing on syntactic analysis. While our code may be valid, and the syntax correct, there is a possibility that the column or table names are inaccurate or nonexistent, yet a plan will be generated. This is why we refer to it as an Unresolved Logical Plan.

The preceding output from the Parsed Logical Plan has confirmed the validity of each element and constructed the initial version of the logical plan, outlining the sequence of execution, including Sort and Inner Join transformations.
Analyzed Logical Plan (Resolved Logical Plan)
Once the Resolved Logical Plan is generated, Spark will perform a semantic analysis using a component known as the Catalog a repository of Spark table, DataFrame, and Dataset information, to cross-verify semantics, column names, and table names. It performs this verification by comparing the provided information with the Catalog.

In the above output, we can now see that Spark has resolved the column type of the two dataframes.
Optimized Logical Plan
The Optimized Logical Plan is created after the Resolved Logical Plan. It uses the Catalyst Optimizer using various rules applied to logical operations and the result is a more efficient execution plan.

We can see above the output, that predicates with the Filter (isnotnull) condition has been pushed down to the LogicalRDD. This optimization aims to decrease the data volume processed by the join operation.
Physical Plan
The Physical Plan is an internal optimization phase for Spark that follows the creation of the Optimized Logical Plan. Its primary role is to specify how the Logical Plan will be executed on the cluster efficiently.
The physical plan generates various execution strategies and evaluates them in a Cost Model. This evaluation estimates the execution time and resource usage for each strategy. The strategy that offers the best optimization is selected as the Best Physical Plan or Selected Physical Plan.
To get a physical run explain with formatted mode.
join_result.explain(mode="formatted")

Code Generation
Once the Best Physical Plan is chosen, the next step is to generate executable code, represented as a Directed Acyclic Graph (DAG) of Resilient Distributed Datasets (RDDs). This code is designed for distributed execution on the cluster, a process referred to as Codegen. The responsibility for this task falls to Spark’s Tungsten Execution Engine.