


Apache Airflow: an open-source platform designed for orchestrating complex workflows. Airflow’s Directed Acyclic Graphs (DAGs) provide a visual representation of pipeline tasks and their dependencies...

In Apache Spark versions before 3.0, the common performance issues encountered are: Data skewness, inadequate partitioning, causing uneven distribution. Suboptimal query plan choices, where Spark...
Apache Spark is one of the most used distributed engines to deal with large amounts of data. Multiple tools can be used to run Spark: Spark Standalone, Apache Hadoop Yarn, Apache Mesos, and...

In this article, we will explore how leveraging Predicate Pushdown can enhance the performance of your Spark SQL queries, providing insights into a powerful optimization technique for efficient data...

In Apache Spark, it’s well-known that using User-Defined Functions (UDFs), especially with PySpark, can aggressively compromise your application’s performance. In this article, we’ll explore why and...

Docker is a powerful containerization technology that allows you to package and distribute applications along with their dependencies in a consistent and portable way. One of the key components of...

When working with Apache Spark, it’s crucial to understand the concepts of logical and physical plans, as they play a pivotal role in the execution of your data processing tasks. In this blog post, we...

It is standard security practice to isolate secrets from code, and developers should not concern themselves with the origin of these secrets. This is where HashiCorp Vault comes in to centralize those...
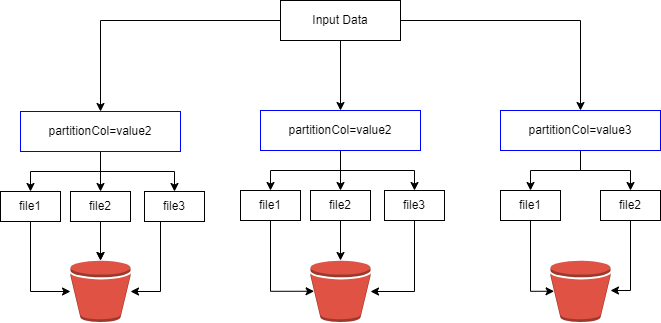
One of Apache Spark’s key features is its ability to efficiently distribute data across a cluster of machines and process it in parallel. This parallelism is crucial for achieving high performance in...
- 1
- 2