

In Apache Spark, it’s well-known that using User-Defined Functions (UDFs), especially with PySpark, can aggressively compromise your application’s performance. In this article, we’ll explore why and how UDFs can impact performance. Let’s dive into the intricacies of Apache Spark UDF impacts on performance.
What are User-Defined Functions (UDFs)?
Before we get started, let’s briefly review what UDFs are. As the name suggests, UDFs are functions created by the user (developer) to perform specific operations on the data. They allow developers to extend the built-in functionalities of Spark (PySpark) by providing a way to apply custom transformations on the data. This extension is done by leveraging Apache Spark UDF for custom tasks.
In the code below, we created a UDF named upper_case that converts the values of the column name to uppercase within the DataFrame called df.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, udf
spark = SparkSession.builder.appName('udf-example').getOrCreate()
columns = ["id", "name"]
data = [("1", "name_1"), ("2", "name_2"), ("3", "name_3")]
df = spark.createDataFrame(data=data, schema=columns)
@udf(returnType=StringType())
def upperCase(str):
return str.upper()
df.select(col("id"), upper_case(col("name")).alias("upper_name")).show()Bellow the output of udf:
+---+----------+
|id |upper_name|
+---+----------+
|1 |NAME_1 |
|2 |NAME_2 |
|3 |NAME_3 |
+---+----------+
PySpark Data Flow
It’s important to understand how UDFs are executed before discussing the drawbacks of using them.
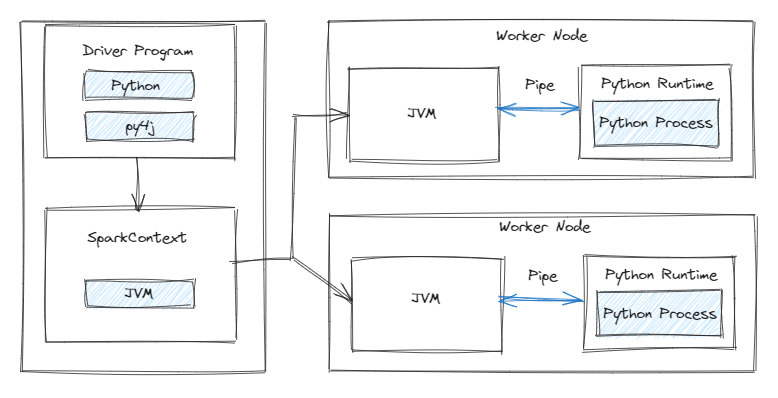
The Apache Spark engine is built using Java and Scala languages, both of which operate on the Java Virtual Machine (JVM). When utilizing the PySpark API, there is a need for interaction between the JVM and the Python Runtime. This interaction is facilitated by a library known as py4j, allowing the invocation of code from the JVM. Simultaneously, each Spark worker runs a Python Runtime to, for example, execute User-Defined Functions (UDFs). Here, we see the complexity involved with Apache Spark UDF use cases.
In the case of executing DataFrame transformations with native or SQL functions, these transformations take place within the JVM itself, where the function’s implementation resides. However, when employing Python UDFs, a distinct process unfolds. Firstly, the code cannot be executed within the JVM; instead, it must run in the Python Runtime. To achieve this, each row of the DataFrame is serialized, transmitted to the Python Runtime, processed, and then returned to the JVM (depicted as a Pipe in the image below). As one might infer, this process is far from optimal.
UDFs Limitations
Here, we’ll discuss the limitations and issues you may encounter when using UDFs.
1. Performance Implications
One of the primary reasons to be wary of UDFs in PySpark is their impact on performance. UDFs are executed row-wise, and each row is processed individually. This row-wise operation can lead to significant performance overhead, especially when dealing with large datasets. PySpark leverages its native functions to perform operations in a distributed and optimized manner, and relying on UDFs may negate these advantages. This is why an in-depth understanding of Apache Spark UDF performance issues is critical.
2. Limited Optimization Opportunities
PySpark has an optimization engine that analyzes and enhances the execution plan of a Spark job. However, UDFs limit the extent to which the optimizer can improve performance.
Native PySpark functions can be optimized more effectively, benefiting from Spark’s internal optimizations and code generation capabilities. This limitation becomes increasingly critical as the dataset size grows, and optimization becomes paramount for efficient processing.
3. Type Safety and Debugging Challenges
UDFs often lack the type of safety and debugging features provided by native PySpark functions. The absence of proper type checking can result in runtime errors that are difficult to trace and resolve.
Debugging UDFs might also be more challenging compared to debugging code written using PySpark’s built-in functions, which are designed to provide clear error messages and facilitate the debugging process.
4. Potential for Non-Deterministic Behavior
UDFs may introduce non-deterministic behavior, especially if they rely on external libraries or mutable states. PySpark strives for determinism to ensure consistent results across different runs and environments.
The use of UDFs that violate this principle can lead to unpredictable outcomes, making it harder to maintain and troubleshoot PySpark applications.
5. Resource Intensiveness
UDFs can be resource-intensive, consuming more memory and processing power than native PySpark functions. This can impact the scalability of your Spark application, limiting its ability to handle larger datasets or increasing the risk of running out of resources, particularly in cluster environments. Thus, careful consideration is required before using Apache Spark UDF in such scenarios.
Conclusion
In this article, we explored why it’s crucial to avoid using UDFs, as in most use cases, there will be a built-in PySpark function or SQL function that can solve your problem. So, before considering using UDFs, ask yourself if your problem can be resolved using existing PySpark functions or their combination. Also, check if there is a SQL function designed for your specific purpose. Understanding these factors can help you decide when to use or avoid Apache Spark UDFs effectively.